Sometimes, we need to work with data which is seems to be correct but in fact is not.
It often happens especially with telemetry data, collected by different sensors, like humidity or temperature. Something might go wrong.
Lets consider such situation. For example we have some temperature observations in the room during a winter.
import numpy as np
data = [24, 24, 24, 22, 16, 26, 15, 24, 16, 26, 18,
20, 16, 50, 23, 22, 25, 42, 18, 19, 17, 21,
26, 19, 16, 20, 17, 23, 22]
print("Array len; %d, mean: %0.3f, median: %0.3f, std: %0.3f" \
% (len(data), np.mean(data), np.median(data), np.std(data)))
# this will be an output:
# >>> Array len; 29, mean: 22.448, median: 22.000, std: 7.323
Well, nothing strange so far, ain't it?. Sure, we might spot abnormal values just looking on the list. but what if we have a list with thousands of elements?
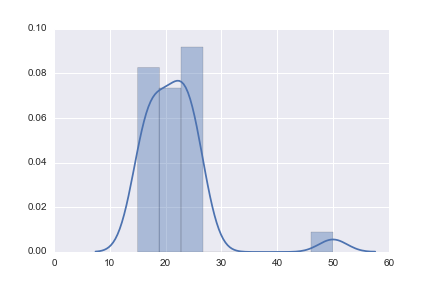
There is an easy way to spot it on the graph:
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(data)
plt.show()
This code with plot you this graph, where you can easily find an abnormal observation.

If you dont have a seaborn or don't want to deal with it, you can just try to use standard hist method from matplotlib:
import matplotlib.pyplot as plt
plt.hist(data)
plt.show()
It will plot you this (yes, it's less fancy, but still a quick and essential python tool):

Te be certainly sure we could try to look on measures of
central tendency.
Just sort your data and try to look at mean, median and standatd deviation throwing out some max elements:
data = sorted(data)
print("Whole data - mean: %0.3f, median: %0.3f, std: %0.3f" \
% (np.mean(data), np.median(data), np.std(data)))
for i in range(1, 3):
data_slice = data[:-i]
print("Without %d max elem - mean: %0.3f, median: %0.3f, std: %0.3f" \
% (i, np.mean(data_slice), np.median(data_slice), np.std(data_slice)))
And here you can spot a significant change in standard deviation without a single element:
Whole data - mean: 21.750, median: 21.500, std: 6.434
Without 1 elem - mean: 20.704, median: 21.000, std: 3.505
Without 2 elem - mean: 20.500, median: 20.500, std: 3.411
Literally it means that your data
might contain some outliers, because it is much more accurate and less spread even without a single element. But to be 100% sure we need to do more math.
Which I'm going to reveal in the next part very soon.
Stay tuned and love your data.